Tư duy vượt khó kiểu “con nhà nghèo”
Vào khoảng 5-6 năm trước, một số Trường Đại học ở Việt Nam như Trường Đại học Kinh tế Quốc dân, Trường Đại học Kinh tế TP Hồ Chí Minh, Trường Đại học Hoa Sen… đã mua các phần mềm kiểm tra đạo văn của nước ngoài để đánh giá bài làm hay các sản phẩm học thuật của người học. Tuy nhiên điểm yếu của các phần mềm ngoại là chỉ bán theo số lượng lớn tài khoản cho các đơn vị với chi phí bản quyền cao nên những người có nhu cầu kiểm tra cá nhân lại không thể sử dụng. Thêm vào đó, do chưa được tối ưu cho xử lý tiếng Việt - “ngôn ngữ vốn cần phát hiện trùng lặp theo cả một đoạn dài thay vì so sánh kiểu word by word như một số ngôn ngữ khác” (chia sẻ của nhóm nghiên cứu Trường Đại học Công nghệ), việc dùng các phần mềm này cho các tài liệu trong nước cũng chưa thực sự hiệu quả.
Điều đó đã thôi thúc nhóm nghiên cứu bao gồm các giảng viên và sinh viên của Trường Đại học Công nghệ, Trường Đại học QGHN thực hiện ý tưởng: “phải xây dựng được hệ thống kiểm tra trùng lặp đáp ứng được nhu cầu sử dụng tại Việt Nam, từ đó góp phần thúc đẩy sự nghiêm túc trong nghiên cứu và học tập trong nước”.
Giao diện trang chủ phần mềm DoIT
Việc xây dựng một phần mềm chống đạo văn như vậy đòi hỏi phải giải quyết rất nhiều vấn đề từ thu thập và xử lý dữ liệu cho đến công tác bảo mật và trải nghiệm người dùng. Nhưng theo anh Nguyễn Ngọc Sơn - cựu sinh viên trường Trường Đại học Công nghệ, thành viên nghiên cứu chính và hiện đang làm việc tại Công ty Cổ phần Metis, cái khó nhất và quan trọng nhất làm nhóm nghiên cứu phải “đau đầu” chính là “làm sao để có thể phát hiện sự tương đồng trong văn bản trên hàng terabytes dữ liệu trên internet mà vẫn phải đảm bảo chất lượng, tốc độ kiểm tra cũng như khả năng chịu tải trên một hạ tầng phần cứng bị giới hạn”.
“Bài toán này giống như bài toán của các công cụ tìm kiếm, tuy nhiên khác nhau ở chỗ: khi tìm kiếm trên Google, Cốc Cốc, người dùng thường tìm những từ khóa ngắn và có thể lặp lại, trong khi đó hệ thống trùng lặp lại luôn phải xử lý những câu văn dài nên khó áp dụng được các phương pháp tối ưu truy vấn của công cụ tìm kiếm. Thêm vào đó, dung lượng tính toán cũng thường cao hơn nhiều so với các từ khóa ngắn”, Nguyễn Ngọc Sơn giải thích.
Với một nhóm nghiên cứu không có quá nhiều tiềm lực để đầu tư vào cơ sở hạ tầng, họ lựa chọn tối ưu thuật toán và công nghệ trên tài nguyên đã có. Tư duy “con nhà nghèo nên phải vượt khó” đã đưa họ đến việc thiết kế hệ thống để cân bằng tải, sử dụng các kiến trúc và công nghệ mới như kiến trúc vi dịch vụ (microservices) và hàng đợi (queue) để các tài liệu gửi lên luôn luôn được đẩy vào danh sách “xếp hàng”. Nhờ vậy, khi có số lượng người dùng lớn, hệ thống cũng không bị quá tải mà luôn xử lý theo giới hạn xử lý tối đa của phần cứng. Song song với đó, nhóm cũng liên tục thử trên rất nhiều thư viện lập trình và nền tảng công nghệ khác nhau, từ trả phí đến mã nguồn mở, cũng như từ các thuật toán tương đồng đến các công nghệ big data và các hạ tầng phần cứng ở nhiều nơi để tìm ra giải pháp tối ưu tốc độ truy vấn tương đồng và đảm bảo kết quả trả về một cách nhanh nhất.
Sau gần bảy năm “đập đi xây lại” cũng như trải qua 4 phiên bản khác nhau, nhóm đã xây dựng và phát triển hoàn thiện được hệ thống hỗ trợ nâng cao chất lượng tài liệu DoIT phục vụ nhu cầu sử dụng của hàng ngàn thầy cô, sinh viên mỗi năm. Không chỉ được tích hợp khả năng kiểm tra chính tả, kiểm tra bài tập theo nhóm, hỗ trợ nhiều loại định dạng văn bản khác nhau và có thể áp dụng triển khai nội bộ cho các đơn vị, theo Nguyễn Ngọc Sơn, điểm vượt trội nhất của phần mềm này là khả năng xử lý tiếng Việt so với các phần mềm khác trên thế giới. Nhờ phát triển được một thuật toán riêng, sử dụng độ đo bất đối xứng nên việc kiểm tra, tính điểm trùng lặp giữa một câu văn ngắn và một câu văn dài trở nên chính xác hơn; hệ thống cũng phát hiện được cả những ký tự ẩn bất thường trong văn bản mà học viên có thể sử dụng để “lách luật”.
Mục tiêu xây dựng cộng đồng chia sẻ dữ liệu
Thực tế những phần mềm phát hiện đạo văn trên thế giới đã được nghiên cứu và áp dụng từ hơn 20 năm nay, tuy nhiên ở Việt Nam, việc phát triển hệ thống này lại khá khó khăn và có rất ít nhóm thực hiện được. Điểm mấu chốt nhất của phần mềm kiểm tra đạo văn không chỉ là công nghệ xử lý dữ liệu lớn mà chính là cơ sở dữ liệu (CSDL) để hệ thống có thể so sánh. Với những phiên bản đầu tiên, dữ liệu để nhóm nghiên cứu của Trường Đại học Công nghệ kiểm tra đến từ những kho tài liệu phổ biến tại Việt Nam như Wikipedia, tailieu.vn hay 123doc. Đồng thời, nhóm cũng xây dựng một hệ thống riêng để có thể tự động phát hiện và thu thập nguồn dữ liệu mới, “khi hệ thống của mình không kiểm tra được một câu văn trùng lặp với bất kỳ câu văn nào trên CSDL thì sẽ thực hiện kiểm tra câu ấy trên Google, khi có nguồn mới rồi thì hệ thống sẽ tự động thu thập về, và bổ sung vào nguồn dữ liệu chính của mình”, anh Nguyễn Ngọc Sơn giải thích.
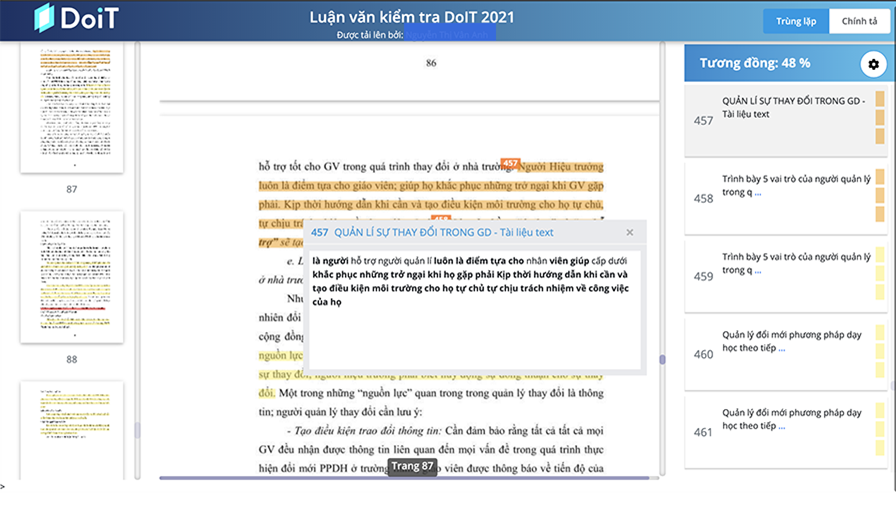
Kết quả kiểm tra trùng lặp của một tài liệu trong hệ thống DoIT
Tuy nhiên, dù đang có khoảng hơn 300 triệu dữ liệu tiếng Anh và 50 triệu dữ liệu tiếng Việt, thì nguồn dữ liệu quan trọng nhất và cũng là dữ liệu mà nhóm thực sự muốn làm giàu cho CSDL, chính là dữ liệu nội sinh, các khóa luận, luận văn, luận án,... từ các Trường Đại học. “Dữ liệu nội sinh sẽ có giá trị cao hơn rất nhiều dữ liệu trôi nổi trên internet, bởi dữ liệu trên internet có những giới hạn: ví dụ như người dùng tải lên thì mình mới lấy được và nhiều trang web cũng không chia sẻ miễn phí đầy đủ nội dung các tài liệu”, nhóm nghiên cứu cho biết. Nếu không có bộ CSDL đủ lớn, phần mềm phát hiện đạo văn dù có tối tân đến đâu cũng không thể phát huy hết hiệu quả.
Thực tế này cũng có thể thấy ngay cả với việc Việt Nam áp dụng Turnitin - phần mềm có cơ sở dữ liệu học thuật trên thế giới rất đồ sộ với tổng cộng khoảng 45 tỷ trang web, hơn 337 triệu bài làm của sinh viên và hơn 130 triệu bài viết từ các cuốn sách và các ấn bản học thuật, thì cũng gặp phải hạn chế do không thể cập nhật cơ sở dữ liệu của tất cả các Trường Đại học, cơ sở nghiên cứu trong nước bởi vẫn có quá ít các đơn vị sử dụng, TS. Nguyễn Lưu Bảo Đoan, Khoa Kinh tế, Trường Đại học Kinh tế TP Hồ Chí Minh cho biết vào năm 2018. Theo ông, phần mềm chỉ có thể giám sát hiệu quả nếu ngày càng có nhiều Trường Đại học số hóa dữ liệu tốt.
Đây cũng chính là mục tiêu mà nhóm nghiên cứu trường Trường Đại học Công nghệ hướng đến: xây dựng được một cộng đồng liên kết và chia sẻ dữ liệu giữa các đơn vị đào tạo. “Khi có cơ sở dữ liệu như vậy, việc phát hiện sự trùng lặp sẽ chính xác hơn rất nhiều”, anh Nguyễn Ngọc Sơn khẳng định. Dù truy cập mở, tài nguyên giáo dục mở đang là xu hướng ở nhiều quốc gia trên thế giới, tuy nhiên tại Việt Nam, việc thuyết phục các đơn vị tham gia vẫn khá khó khăn do nhiều đơn vị lo ngại vấn đề bảo mật, mất mát dữ liệu. Hiện ngoài các trường trong Đại học Quốc gia Hà Nội, nhóm đang có thêm ba Trường Đại học khác hợp tác chia sẻ dữ liệu nội sinh.
Đối mặt với không ít thách thức như vậy nhưng nhóm nghiên cứu vẫn đang liên tục cải tiến phần mềm như nghiên cứu để loại trừ các câu văn phổ thông (ví dụ lời cảm ơn, phụ lục) trong trùng lặp văn bản, đồng thời tiếp tục phát triển thêm các phần mềm liên quan đến dữ liệu, tri thức và giáo dục như Simidoc, EasyCheck, VOJS. Hiện tại, nhóm cũng đang đẩy mạnh chuyển giao công nghệ và thương mại hóa sản phẩm. Yếu tố lớn nhất giữ cho họ vẫn miệt mài hoàn thiện phần mềm này sau 7 năm thay vì dừng lại ở một đề tài nghiên cứu trong trường không chỉ là tiềm năng ứng dụng mà còn là những giá trị mà nhóm thấy được từ việc có một cơ sở dữ liệu và hệ thống hiệu quả để kiểm tra đạo văn trong nước. “Nếu không có công cụ hỗ trợ, giáo viên dù thấy bài làm quen quen nhưng cũng sẽ khó tìm được tài liệu để đối chứng. Chúng tôi hi vọng phần mềm sẽ góp phần vào việc nâng cao chất lượng giáo dục và thúc đẩy sự nghiêm túc, chuyên nghiệp và cả sáng tạo trong học tập và nghiên cứu của sinh viên, học viên”, nhóm nghiên cứu kỳ vọng.
|
Hệ thống nâng cao chất lượng văn bản - DoIT đã đạt giải Nhì Nhân tài Đất Việt 2017. Bên cạnh đó, quy trình kiểm tra trùng lặp trong nhóm văn bản cũng đã được Cục Sở hữu trí tuệ cấp bằng độc quyền sáng chế số 1-0026606, công bố ngày 25/12/2020.
Hiện nay, hệ thống nâng cao chất lượng tài liệu DoIT đã được sử dụng ở khoảng 15 trường như Trường Đại học Quốc Gia Hà Nội, Trường Đại học Luật, Trường Đại học Vinh,... và được người dùng cá nhân từ 60 trường trải nghiệm. Mỗi ngày, vào thời điểm cao điểm như mùa nộp khóa luận, hệ thống DoIT xử lý từ 700 đến hàng nghìn tài liệu với tốc độ xử lý trung bình cho khoảng 50 trang là 1 phút. “Người dùng không có cảm giác phải chờ đợi nhiều và hệ thống có thể đáp ứng tốt với lượng truy cập và sử dụng như hiện tại”, nhóm nghiên cứu cho biết.
|